Máxima: " Hegel dice que la identidad es la determinación de lo simple inmediato y estático, mientras que la contradicción es la raíz de todo movimiento y solamente aquello que encierra una contradicción se mueve"
Máxima "Carl Friedrich Gauss: No es el conocimiento, sino el acto de aprendizaje; y no la posesión, sino el acto de llegar a ella, lo que concede el mayor disfrute"
En 1970 viendo las carreras con mi padre, Carlos Zavarce Peréz, presencié el primer empate en una carrera de caballos, fue entre Senador y Paunero, ahí empezó mi pasión por las carreras de caballo (Hipismo) y los números.
Así empecé a conocer y a ver muchas estadísticas, la cual me llevaría en un futuro, quién lo iba a imaginar, a estudiar dicha profesión, en la siguiente figura observen un folleto de una carrera del Hipódromo La Rinconada la cual contiene cantidad de información resumida de cada ejemplar, que cantidad de números tiene lo que aquí en Venezuela, le llamamos la Gaceta, esta revista tiene mucha información, un resumen de cada una de las actuaciones de cada caballo pura sangre, entre las variables están el peso (kg) del ejemplar y el jinete, la distancia (metros), tiempo (en segundos), posición e la carrera anterior, etc. como se ve muchas variables cuantitativas discretas y continuas y algunas variable cualitativas como el nombre de los padres del ejemplar, comentario del pronosticador, dueños del caballo, etc.
Si por ejemplo, seleccionamos un ejemplar, podemos observar todos los registros de sus actuaciones en las cuatro (4) últimas competencias, y podemos ordenar la información por distancia o fechas, ver los respectivos tiempos e inferir sobre el posible tiempo de carrera que puede tener el ejemplar en la nueva competencia, ademas de ver si el caballo aumentó de peso o no, si su rendimiento es mejor en carreras largas o cortas, y así ver un sin fin de información, para la toma de decisiones a la hora de realizar un pronostico.
En 1971: un ejemplar llamado Cañonero de Venezuela gana el Kentucky Deby, primero de la Triple Corona Norteamericana, con Gustavo Avila como Jinete y preparador juan Arias y nos da una gran alegría a los hípicos de Venezuela.
Hace 47 años de la victoria de Cañonero en el Preakness Stakes con la extraordinaria conducción de Gustavo Avila @gustavoavilacom Narracion Aly Khan, el mejor de América En la siguiente dirección electrónica puedes observar la la segunda de la triple corona ganada por Cañonero, jinete Gustavo Avila, preparador Juan Arias, de Venezuela. https://twitter.com/twitter/statuses/996575466625564673
Aquí tenemos sus estadísticas
En 1973: Secretariat El mejor caballo de la historia, sus marcas no han sido superadas, gana la triple corona norteamericana.
Historia de Secretariat
En el 2015: Después de 37 años, un ejemplar llamado American Pharoah gana la triple corona norteamericana
Este video compara los tiempos de Secretariat y American PharoaH, estadisticamente "impresionante"
En el 2018: Justify ganador del Kentucky Derby primero de la triple corona norteamericana
Que clase de carrera!
El siguiente vídeo año 2018, el Clásico Presidente de la República en La Rinconada
En Venezuela, el hipismo es uno de los deporte preferidos, tiene una gran afición, y con estadísticas para disfrutar.
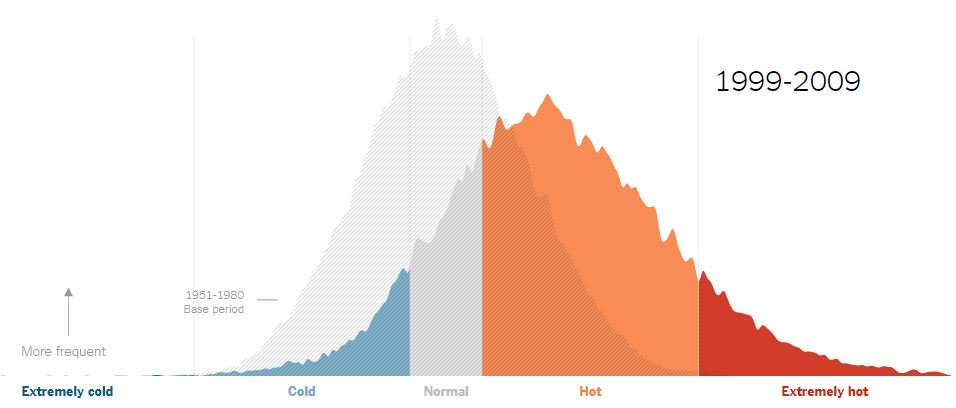
Recientemente, compartieron un buen ejemplo de estadísticas. Crearon curvas que ilustran el cambio climático global a lo largo del tiempo. El gráfico siguiente muestra una curva normal, con la temperatura normal como valor modal.
Pero a medida que avanzamos en el tiempo, los días calurosos se vuelven modales y las curvas ya no se superponen. Algo así como la ilustración clásica de cómo se ve un tamaño de efecto pequeño a mediano en términos de superposición de distribución.
Es importante resaltar, que esta variable cuantitativa continua ( Temperatura) tiene su forma de graficar y representar sus valores, los cuales se aproximan a la curva de la normal .Este gráfico es parte del NYT "¿Qué está pasando en este gráfico?" Dicha serie, que se crean y comparten en asociación con la Asociación Americana de Estadística.
No importa el campo, si un investigador está recolectando datos de cualquier tipo, en algún momento tendrá que analizarlo. Y lo más probable es que recurra a las estadísticas para descubrir qué pueden decirle los datos. La conversación
Una amplia gama de disciplinas, como las ciencias sociales, el marketing, la fabricación, la industria farmacéutica y la física, intentan hacer inferencias sobre una gran población de individuos o cosas basándose en una muestra relativamente pequeña. Pero muchos investigadores están usando técnicas estadísticas anticuadas que tienen una probabilidad relativamente alta de conducirlas mal. Y eso es un problema si significa que no comprendemos qué tan bien funciona un fármaco nuevo potencial, o los efectos de algún tratamiento en el suministro de agua de una ciudad, por ejemplo.
Como un estadístico que ha estado siguiendo los avances en el campo, sé que hay métodos muy mejorados para comparar grupos de personas o cosas, así como la comprensión de la asociación entre dos o más variables. Estos métodos modernos y robustos ofrecen la oportunidad de lograr una comprensión de los datos más precisa y matizada. El problema es que estas mejores técnicas han sido lentas para avanzar en la comunidad científica en general.
Cuando los métodos clásicos no lo cortan
Imagine, por ejemplo, que los investigadores reúnen a un grupo de 40 personas con colesterol alto. La mitad toma el medicamento A, mientras que la otra mitad toma un placebo. Los investigadores descubren que aquellos en el primer grupo tienen una disminución media mayor en sus niveles de colesterol. ¿Pero qué tan bien los resultados de solo 20 personas reflejan lo que sucedería si miles de adultos tomaran el medicamento A?O en una escala más cósmica, considere al astrónomo Edwin Hubble, que midió cuán lejos están las 24 galaxias de la Tierra y qué tan rápido se están alejando de nosotros. Los datos de ese pequeño grupo le permiten trazar una ecuación que predice la llamada velocidad de recesión de una galaxia dada su distancia. Pero, ¿qué tan bien reflejan los resultados del Hubble la asociación entre todos los millones de galaxias en el universo si se midieran?
En estas y muchas otras situaciones, los investigadores usan tamaños de muestra pequeños simplemente por el costo y la dificultad general de obtener datos. Los métodos clásicos, enseñados y utilizados rutinariamente, intentan abordar estos problemas haciendo dos suposiciones clave.
Primero, los científicos suponen que hay una ecuación particular para cada situación individual que modelará con precisión las probabilidades asociadas con los posibles resultados. La ecuación más comúnmente utilizada corresponde a lo que se llama una distribución normal. El gráfico resultante de los datos tiene forma de campana y es simétrico alrededor de algún valor central.En segundo lugar, los investigadores suponen que la cantidad de variación es la misma para ambos grupos que están comparando. Por ejemplo, en el estudio de drogas, los niveles de colesterol variarán entre los millones de personas que podrían tomar el medicamento. Las técnicas clásicas suponen que la cantidad de variación entre los posibles receptores de drogas es exactamente la misma que la cantidad de variación en el grupo placebo.
Una suposición similar se hace al estudiar asociaciones. Considere, por ejemplo, un estudio que examine la relación entre la edad y alguna medida de depresión. Entre los millones de personas de 20 años, habrá una variación entre sus puntajes de depresión. Lo mismo es cierto a los 30, 80 o cualquier edad en el medio. Los métodos clásicos suponen que la cantidad de variación es la misma para cualquier dos edades que podamos elegir.
Todos estos supuestos permiten a los investigadores utilizar métodos que son teórica y computacionalmente convenientes. Desafortunadamente, es posible que no arrojen resultados razonablemente precisos.
Mientras escribía mi libro "Introducción a la estimación robusta y las pruebas de hipótesis", analicé cientos de artículos de revistas y descubrí que estos métodos pueden no ser confiables. De hecho, las preocupaciones sobre los resultados teóricos y empíricos datan de hace dos siglos.
Cuando los grupos que los investigadores están comparando no difieren de ninguna manera, o no hay asociación, los métodos clásicos funcionan bien. Pero si los grupos difieren o existe una asociación, que ciertamente no es poco común, los métodos clásicos pueden fallar. Las diferencias y asociaciones importantes pueden pasarse por alto y pueden derivarse inferencias altamente engañosas.Incluso el reconocimiento de estos problemas puede empeorar las cosas si los investigadores tratan de evitar las limitaciones de los métodos estadísticos clásicos utilizando métodos ineficaces o técnicamente inválidos. Transformar los datos o descartar valores atípicos, cualquier punto de datos extremos que estén lejos de los otros valores de datos, estas estrategias no necesariamente solucionan los problemas subyacentes.
Un nuevo camino
Los recientes avances importantes en las estadísticas proporcionan métodos sustancialmente mejores para hacer frente a estas deficiencias. En los últimos 30 años, los estadísticos han solidificado la base matemática de estos nuevos métodos. Llamamos a las técnicas resultantes robustas, porque continúan funcionando bien en situaciones donde los métodos convencionales se caen.
Los métodos convencionales proporcionan soluciones exactas cuando se cumplen todos los supuestos mencionados anteriormente. Pero incluso las ligeras violaciones de estas suposiciones pueden ser devastadoras.
Los nuevos métodos robustos, por otro lado, brindan soluciones aproximadas cuando estas suposiciones son verdaderas, haciéndolas casi tan precisas como los métodos convencionales. Pero es cuando la situación cambia y las suposiciones no son ciertas que los nuevos métodos robustos brillan: siguen brindando soluciones razonablemente precisas para una amplia gama de situaciones que causan problemas de las formas tradicionales.Una preocupación específica es la situación que ocurre comúnmente donde los gráficos de los datos no son simétricos. En un estudio que se ocupa de la depresión entre adultos mayores, por ejemplo, un gráfico de los datos es muy asimétrico, más o menos porque la mayoría de los adultos no están demasiado deprimidos.
Los valores atípicos son otro desafío común. Los métodos convencionales suponen que los valores atípicos no tienen importancia práctica. Pero, por supuesto, eso no siempre es cierto, por lo que los valores atípicos pueden ser desastrosos cuando se usan métodos convencionales. Los métodos robustos ofrecen una forma técnicamente sólida, aunque no obvia, basada en el entrenamiento estándar, para tratar este problema que proporciona una interpretación mucho más precisa de los datos.
Otro avance importante ha sido la creación de métodos bootstrap, que son técnicas inferenciales más flexibles. La combinación de métodos robustos y bootstrap ha llevado a una amplia gama de técnicas nuevas y mejoradas para comprender los datos.
Estas técnicas modernas no solo aumentan la probabilidad de detectar diferencias y asociaciones importantes, sino que también brindan nuevas perspectivas que pueden profundizar nuestra comprensión de lo que los datos intentan decirnos. No hay una perspectiva única que siempre proporcione un resumen preciso de los datos. Las perspectivas múltiples pueden ser cruciales.
En algunas situaciones, los métodos modernos ofrecen poca o ninguna mejora sobre las técnicas clásicas. Pero hay una amplia evidencia que ilustra que pueden alterar sustancialmente nuestra comprensión de los datos.
Graphical interpretations of data: An introduction
Written by Allan Reese on .
This is the first of a series of articles on the design of simple graphs – graphs you could draw with pencil and ruler but are now more likely to be produced using software. You can find examples in the book Plain Figures1 covering the presentation of statistics by graphs and tables. Despite that and other sources of advice, simple two-dimensional graph forms often fail to communicate as their maker intended – or so one assumes.
Computer “visualisations” often strike me as misguided. Those, in particular, that involve a simulated third dimension or animations may show off sophisticated computing power, but the outcome is style over substance.
My contention over many years has been that many simple graphs in published papers are not edited or proofread with anything like the attention paid to text. Such graphs may as a result be confusing, ambiguous or actually in conflict with the message in the text. It has been easy for several decades to generate graphs using popular software on personal computers; unfortunately, the assumption has been that because a graph came directly from data it must be in some sense “correct”.
I hope these articles will be read as constructive debate, drawing attention to aspects where clarity can be improved. It is, however, an unusual activity, and some authors, I have found, resent the inference that they may have failed. As one journal editor wrote to me, “Nobody else has flagged this up as an issue, and if poor graphical presentation of data were sufficient basis for a published critique, then the pages of journals would be full of them.”
It is virtuous to start with a little selfexamination using an example from Significance. Figure 1 in “What is the most popular birthday in England and Wales?”,2 reproduced here also as Figure 1, shows a simple line graph of the data series for the numbers of births for each calendar date averaged over 36 years.
FIGURE 1 The original graphic, showing mean frequencies of live births by birthday in England and Wales, 1979–2014.
While the graph is arithmetically correct, it can be improved as a presentation. An important distinction must be made between graphs drawn during the course of analysis as tools for insight, and graphs drawn after the analysis as a presentation for communicating results. Just as writers must choose words and place them in order to clarify or stress meaning, graphs need to be considered and revised to emphasise the intended message.
The first point is that the main feature of the graph occurs over the end of the year. The reader has to mentally join up the peak on 30/31 December with the low value on New Year’s Day. One technical fix suggested for cyclic data is to duplicate part of the cycle: repeat the line for January at the right. That would also allow more space to label the point for 27 December on its right so that it does not appear to fall between Christmas Eve and Christmas Day. My preference, however, is to move the origin and start the year at a bland part of the cycle. For example, starting at 1 March brings all the interesting parts of the line towards the centre; it also moves the leap day, 29 February, which is notably unremarkable, to the end – almost an afterthought.
The vertical range of the plot was apparently determined by the range of data (using round values probably selected by the software). Hence the importance of the drop is not made visual. It is a standard trick in advertising and public relations to scale thus so as to make changes, for example in share price, look either trivial or dramatic. One very common injunction for scientific graphs is that you must always include zero. While once again arithmetically correct, the result may be to make changes appear less than interesting. Inserting a break in the axis, with zero at a completely arbitrary distance, is an utterly illogical suggestion.
Rather than follow blind rules, one needs to consider what comparisons are being presented, and hence what is the relevant reference value. Here it is the usual range of day-to-day variation, or some measure that distinguishes short periods of large fluctuation from the apparent general cyclic trend. This graph is expository rather than suggesting some physical relationship. Adding lines at percentiles of the data gives a visual indication of the Christmas drop compared to the “usual range”. Making the mean (the median is almost identical) bolder makes the seasonal pattern over spring and summer more evident.
The revised graph (Figure 2) is labelled with the data values on one side and proportions of the mean at chosen percentiles on the other. Labelling will be discussed in more detail in another column.
FIGURE 2 The revised graphic, again showing mean frequencies of live births by birthday in England and Wales, 1979–2014.
The day-to-day variation shown by the plotted line might be random, but when investigated in months without public holidays we find a regular weekly periodicity. You might hope that averaging over years would eliminate day-of-week effects, except that over 36 years the combination of weekdays changes from date to date. The original article highlighted a weekend effect. The pattern of leap days makes it very hard to find a span of years that does not suffer this problem.
Showing variation that is an artefact of the period of observation is distracting in a presentation. A solution is to smooth the daily counts with a seven-day running mean for each date, remembering that the dates wrap round at the end of year. The daily values can still be shown, but faded into the background, except over the Christmas period when fixeddate holidays predominate. It is worth noting that 27 December may be a public holiday when Christmas Day falls on a weekend; this happens in 10 out of 36 years. The smoothed line also shows more clearly the dips at the start and end of May and end of August, where public holidays vary annually over a small range of dates.
Figure 2 makes these and other changes. The choices made are, like the choices of words in the text, personal and cannot be claimed to be unique or definitive. A design problem has no uniquely right answers, but there are questions that should be asked. What is clear now is that the 10% of values that, by definition, occur outside the 5th and 95th percentiles do so in the September peak or on public holidays.
Acknowledgements
Thank you to Mario Cortina Borja who provided a copy of the data used in his article; there are small and unimportant differences from values on the Office for National Statistics website. Figure 2 was drawn using Stata 12 for Windows. Running means with wraparound for cyclic data were calculated by a Stata function movsumm written by Nick Cox.
About the author
Allan Reese is an independent statistical consultant and member of the Significance editorial board.
References
Chapman, M. and Wykes, C. (1996) Plain Figures. London: The Stationery Office. ^
Cortina Borja, M. and Martin, P. (2017) What is the most popular birthday in England and Wales? Significance, 14(1), 6–7. ^
La importancia del conocimiento de la Estadística en nuestros días
La Estadística es una rama de las matemáticas más cercana a nuestra vida cotidiana de lo que pensamos. La utilizamos continuamente en nuestro lenguaje, incluso sin darnos cuenta, haciendo familiares términos como población, muestra, porcentaje, media, moda… Hoy en día, cualquier persona informada posee un vocabulario básico de Estadística que utiliza habitualmente y, en la mayoría de los casos, entiende.
Los anuncios publicitarios hablan de porcentajes de descuento en los precios de los productos. Las noticiasde los medios de comunicación divulgan continuamente diferentes estadísticas sobre la intención de voto de los/as electores/as hacia un partido político u otro, la evolución de la tasa de desempleo, las estadísticas de los accidentes de circulación, la tasa de natalidad y mortalidad, la tasa de inflación interanual, el porcentaje de gasto de los gobiernos en cada partida presupuestaria, etc.
Prácticamente todas las ciencias, tanto tecnológicas como sociales, utilizan aspectos fundamentales de la Estadística
En nuestros días, la Estadística se ha convertido en una ciencia aplicada a lo cotidiano que se utiliza como método efectivo para describir y predecir con exactitud hechos y fenómenos de índole muy diversa: políticos, sociales, psicológicos, sanitarios, biológicos, físicos y hasta deportivos. Y es que a medida que ha ido aumentando la complejidad en el mundo, se hace más difícil la toma de decisiones informadas y racionales sin tener un conocimiento objetivo lo más preciso posible de los fenómenos y las situaciones, para lo cual es necesario contar con la orientación que nos proporcionan herramientas de análisis científico altamente confiables como es la Estadística, que nos permitan realizar elecciones acertadas y eficientes, ayudándonos a resolver los problemas de la vida cotidiana. De ahí que actualmente resulte imprescindible aprender y servirse de ella como forma de minimizar la probabilidad de cometer errores.
En términos generales podemos afirmar que la Estadística se puede utilizar para mejorar el rendimiento de la vida diaria, ya que es una guía universal frente a la incertidumbre de lo desconocido.